OpenAI、谷歌等一线大模型科学家公开课,斯坦福CS 25春季上新!
OpenAI、谷歌等一线大模型科学家公开课,斯坦福CS 25春季上新!在斯坦福,有一门专门讲 Transformer 的课程,名叫 CS 25。
来自主题: AI资讯
8277 点击 2025-04-26 19:37
 搜索
搜索
在斯坦福,有一门专门讲 Transformer 的课程,名叫 CS 25。

视频生成领域,又出现一位重量级开源选手。

2025 年 3 月 11 日,语音生成初创公司 Cartesia 宣布完成 6400 万美元 A 轮融资,距其 2700 万美元种子轮融资仅过去不到 3 个月。本轮融资由 Kleiner Perkins 领投,Lightspeed、Index、A*、Greycroft、Dell Technologies Capital 和 Samsung Ventures 等跟投。

AI21Labs 近日发布了其最新的 Jamba1.6系列大型语言模型,这款模型被称为当前市场上最强大、最高效的长文本处理模型。与传统的 Transformer 模型相比,Jamba 模型在处理长上下文时展现出了更高的速度和质量,其推理速度比同类模型快了2.5倍,标志着一种新的技术突破。

现有的可控Diffusion Transformer方法,虽然在推进文本到图像和视频生成方面取得了显著进展,但也带来了大量的参数和计算开销。
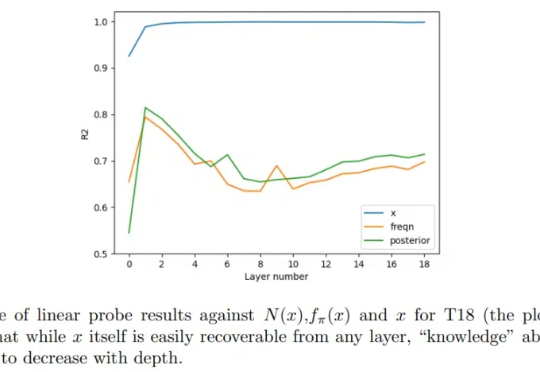
Transformer 很成功,更一般而言,我们甚至可以将(仅编码器)Transformer 视为学习可交换数据的通用引擎。由于大多数经典的统计学任务都是基于独立同分布(iid)采用假设构建的,因此很自然可以尝试将 Transformer 用于它们。
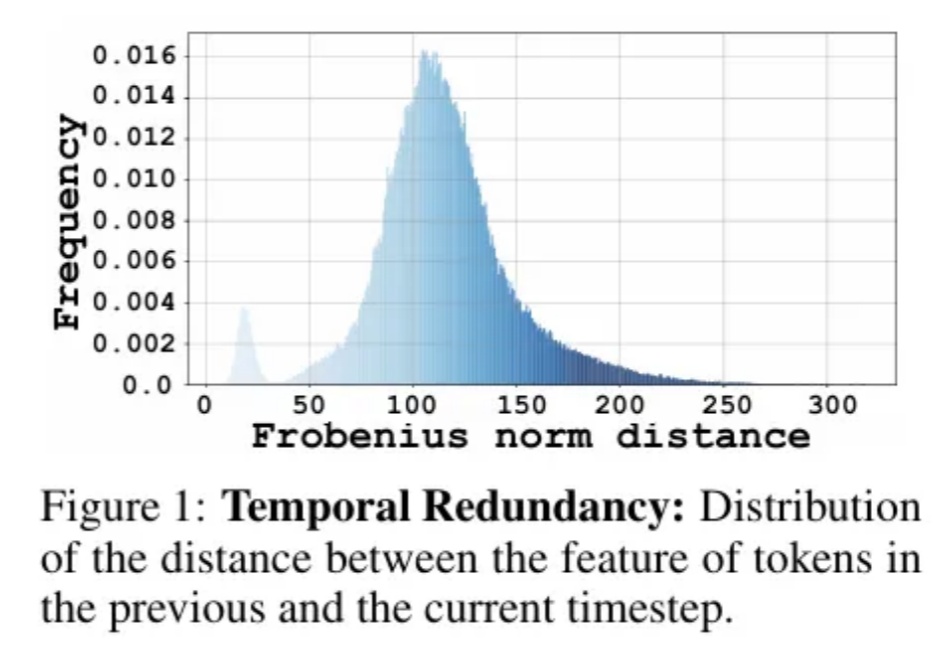
Diffusion Transformer模型模型通过token粒度的缓存方法,实现了图像和视频生成模型上无需训练的两倍以上的加速。

当前的 AI 领域,可以说 Transformer 与扩散模型是最热门的模型架构。也因此,有不少研究团队都在尝试将这两种架构融合到一起,以两者之长探索新一代的模型范式,比如我们之前报道过的 LLaDA。不过,之前这些成果都还只是研究探索,并未真正实现大规模应用。

进入到 2025 年,视频生成(尤其是基于扩散模型)领域还在不断地「推陈出新」,各种文生视频、图生视频模型展现出了酷炫的效果。其中,长视频生成一直是现有视频扩散的痛点。
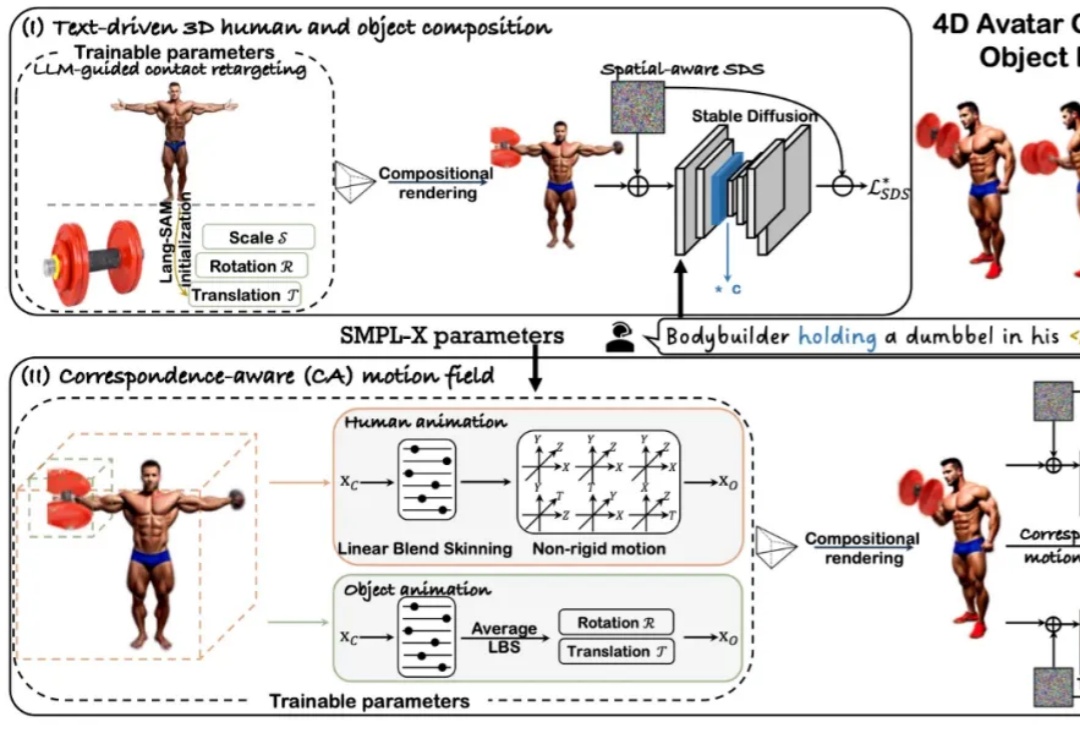
近年来,随着扩散模型和 Transformer 技术的快速发展,4D 人体 - 物体交互(HOI)的生成与驱动效果取得了显著进展。然而,当前主流方法仍依赖 SMPL [1] 这一人体先验模型来生成动作。